This project studies how frozen vision-language-action policies can be adapted to real-world robotic manipulation through lightweight residual reinforcement learning. Rather than fine-tuning the full foundation model, a compact RL controller learns additive action corrections on top of the pretrained policy. Experiments on a 3D-printed SO-101 arm across seven tabletop manipulation tasks show improved task progress and out-of-distribution generalization under object, viewpoint, and dynamic perturbations.

Problem
Generalist robot policies still break at the edge
Robots operating in unstructured, changing environments often encounter conditions that differ from their training data. Vision-language-action policies provide a promising foundation by combining visual perception, language grounding, and action prediction, but real-world robots still fail when the scene shifts beyond the conditions seen during training. A base policy may reach the object, begin the correct motion, and get most of the way through the task, then fail at the final contact-rich stage.
Full fine-tuning is expensive and risks erasing valuable pretrained behaviour. Pure reinforcement learning from scratch has the opposite problem, since real robot data is slow, costly, and physically constrained. The missing piece is a local adaptation mechanism that preserves the broad competence of the pretrained policy while allowing the robot to specialize to its own embodiment, task distribution, and physical environment. This project studies that middle ground through a frozen VLA backbone and a lightweight residual RL controller that learns the last-mile corrections needed for real-world manipulation.
Idea
Instead of fine-tuning the full VLA backbone, this project treats the pretrained policy as a frozen visuomotor prior. The model still sees the camera input, robot state, and language instruction, then proposes the base action. A lightweight residual RL controller sits on top of that action and learns only the correction needed for the robot, task, camera geometry, and local dynamics.
This keeps the useful behaviour learned during pretraining intact, while giving the system a practical way to adapt on real hardware. The base policy gets the robot into the right part of the task. The residual policy learns the last-mile adjustment that turns partial progress into completion.
System Overview




STL layouts of the leader and follower robot components arranged on the Ender 3 printer bed for fabrication.






Experimental Protocol
Overview of Experiments
This experimental suite evaluates residual RL adapters on top of a frozen pre-trained VLA backbone for real-world tabletop manipulation. We compare three controller variants: the unmodified backbone policy, a fine-tuned policy without residual adaptation, and residual RL adapters that learn additive action corrections to the base action. The core objective is to measure how effectively different residual RL algorithms can exploit a fixed pre-trained policy under real distribution shifts.
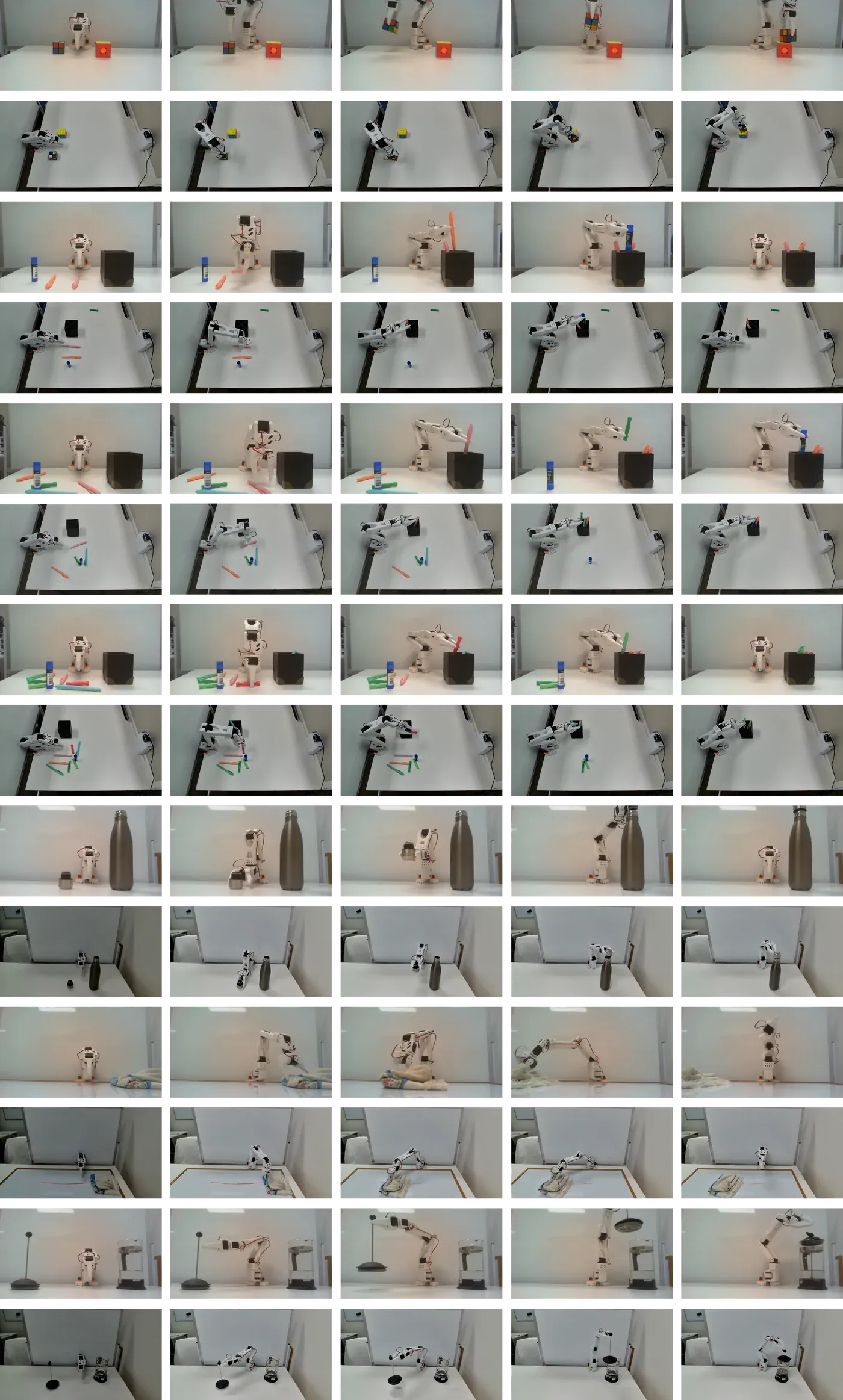
All experiments run on a physical 3D-printed SO-101 robotic arm without simulation. Training and evaluation use only real-world interaction data from teleoperated demonstrations and robot rollouts, so outcomes directly reflect sensor noise, contact variability, and actuation delays.
The suite includes seven tabletop tasks that vary in difficulty, horizon, and contact complexity: stacking Rubik’s cubes, bussing a table at three clutter levels, placing a bottle lid, erasing a whiteboard marker stroke with cloth, and closing a French press. Together these tasks probe perception, precision grasping, dexterous manipulation, and long-horizon behavior.
Task 1: Rubik’s Stack
The rubix-stack-v1 task requires stacking two Rubik’s cubes, with the smaller cube on top of the larger cube. Cubes vary in color and are randomly rotated between episodes, stressing visual perception and precise grasp execution on non-axis-aligned objects.
A rollout is successful when the smaller cube is grasped, lifted, and stably placed on the larger cube without either cube leaving the workspace.




Front and top camera views of the Rubik's Stack workspace used for data collection and evaluation.
Task 2: Bus Table (Easy)
The bus-table-easy-v1 task asks the robot to clear a small tabletop by picking up a few colored pens and a glue stick, then placing them into a pen holder. Glossy objects interacting with a PLA gripper induce slip and require careful approach angles for reliable grasping.
A rollout is successful when all objects are placed in the pen holder and none are pushed or knocked off the table.




Front and top camera views of the Bus Table (Easy) workspace used for data collection and evaluation.
Task 3: Bus Table (Medium)
The bus-table-medium-v1 task increases object count and adds a pen type with fewer reliable grasp points. The longer horizon and sparser rewards test planning and persistence, while the new geometry is a stricter probe of dexterous grasping.
A rollout is successful when all objects are placed in the pen holder and none are pushed or knocked off the table.




Front and top camera views of the Bus Table (Medium) workspace used for data collection and evaluation.
Task 4: Bus Table (Hard)
The bus-table-hard-v1 task further increases clutter with many pens of different shapes, diameters, and colors, plus a glue stick on a crowded tabletop. The robot must choose grasp sequences that avoid chain reactions where one poor approach displaces multiple objects.
A rollout is successful when all objects are placed in the pen holder and none are pushed or knocked off the table.




Front and top camera views of the Bus Table (Hard) workspace used for data collection and evaluation.
Task 5: Close Bottle Lid
The close-bottle-lid-v1 task evaluates precise pose estimation and alignment by requiring the robot to place a metal lid onto its matching metal bottle. Tight clearances around the bottle rim make outcomes highly sensitive to end-effector pose error.
A rollout is successful if the lid is grasped and lifted without being dropped, moved above the bottle opening, and placed so it seats cleanly on the rim. Twisting or screwing is not required.




Front and top camera views of the Bottle Lid workspace used for data collection and evaluation.
Task 6: Erase Whiteboard
The erase-whiteboard-v1 task uses a deformable cloth to remove a red marker stroke from a vertical whiteboard. Deformable contact creates variable contact patches and friction, yielding non-deterministic dynamics that challenge residual compensation.
A rollout is successful when the cloth is grasped, pressed against the board, and moved so the marked region is largely erased with only faint traces remaining.




Front and top camera views of the Erase Whiteboard workspace used for data collection and evaluation.
Task 7: Close French Press
The close-french-press task requires manipulating the French press lid by a thin metal rod that is narrower than the gripper aperture, so the robot stabilizes through surface contact on the knob. The task then requires pressing the plunger against water resistance, combining precise stabilization with forceful actuation.
A rollout is successful if the lid is grasped and lifted without sliding off the rod or knob, positioned over the opening, and the plunger is pressed down until the knob reaches the closed position.




Front and top camera views of the Close French Press workspace used for data collection and evaluation.
Trial Split and Progress Scoring
Each method-task pair is evaluated over 20 physical rollouts. We use a 5-5-10 protocol and log Discretized Task Progress (DTP) per trial so failures are legible by stage rather than collapsed into binary success/failure.
5-5-10 Trial Protocol
Trials 1-5
In-distribution
Trials 6-10
Dynamic perturbation
Trials 11-20
Out-of-distribution
DTP Ladder
- 0.00no useful progress
- 0.25perception / approach
- 0.50contact / partial manipulation
- 0.75near completion
- 1.00task success
We aggregate these trial-level progress scores into three summary metrics: mean progress across all rollouts, OOD generalization over the final ten rollouts, and the residual policy’s generalization gain over the base policy:
Environment Setup for OOD Tests
The tabletop workspace and sensing configuration are designed to induce controlled out-of-distribution (OOD) shifts across visual, dynamical, task, and environmental dimensions while remaining compatible with the seven tasks above. OOD conditions are introduced by modifying object appearance and geometry, contact properties, clutter, and partial failure events across repeated rollouts.
| Shift type | Workspace implementation |
|---|---|
| Visual shift | Vary object color and texture (for example Rubik’s cube faces, pen colors, and metal versus plastic surfaces), adjust ambient lighting intensity and hue, and alter background appearance inside the camera field of view. |
| Dynamics shift | Change object mass and friction (for example pen coatings, metal versus plastic lids, and cloth on whiteboard), or vary table coverings to alter sliding and sticking behavior in contact-rich interactions. |
| Task configuration shift | Scale the number and arrangement of objects (Tasks 2-4), alter initial poses and relative spacing, or require interaction with deformable or partially supported objects (Tasks 5-7). |
| Environmental or clutter shift | Introduce distractor objects and increased clutter around the primary task region, or slightly reconfigure the workspace in the camera frame while keeping the target objects present. |
| Failure and recovery shift | Allow objects to slip, topple, or roll during execution, creating intermediate states that require re-grasping, re-approach, or local replanning instead of a single straight-line solution. |
All conditions are instantiated on the physical SO-101 tabletop setup using real objects, adjustable lighting, and fixed camera viewpoints. Success and failure on OOD trials are determined from synchronized RGB camera recordings and robot telemetry, yielding per-rollout success labels and, where applicable, intermediate progress indicators for reward definition and for reporting success rates and failure modes.
Results
Experimental Results
This section evaluates the residual reinforcement learning framework across seven real-world manipulation tasks. We compare the frozen base policy (pi_base), three pure RL algorithms (TD3, SAC, PPO), and their residual variants (Res-TD3, Res-SAC, Res-PPO). Each task is run for 20 trials, with trials 1-10 in nominal settings and trials 11-20 under OOD conditions with randomized initialization and dynamics perturbations.
Overall Performance Analysis
We begin with aggregate performance over all tasks and all trials to establish the broad ranking of methods.

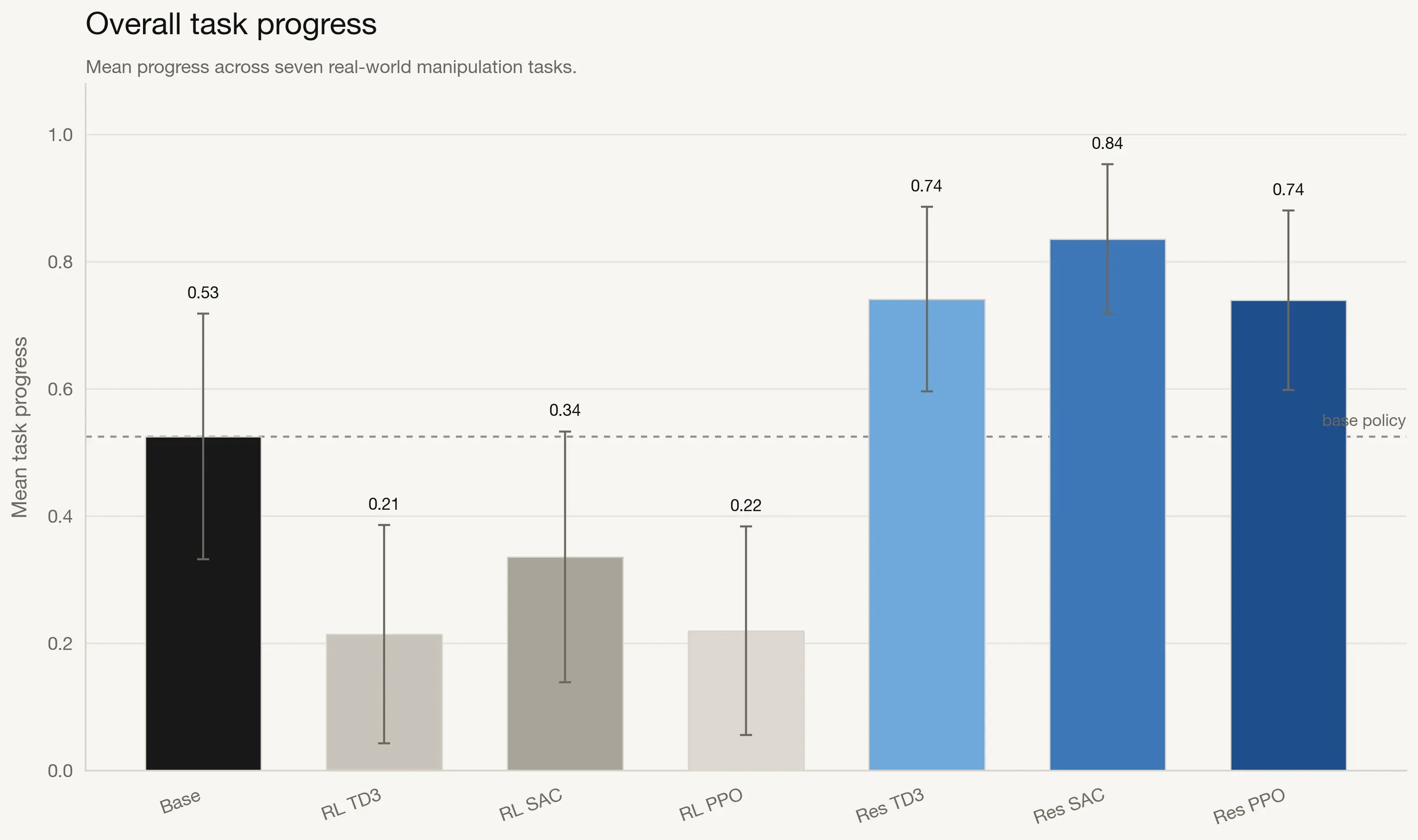

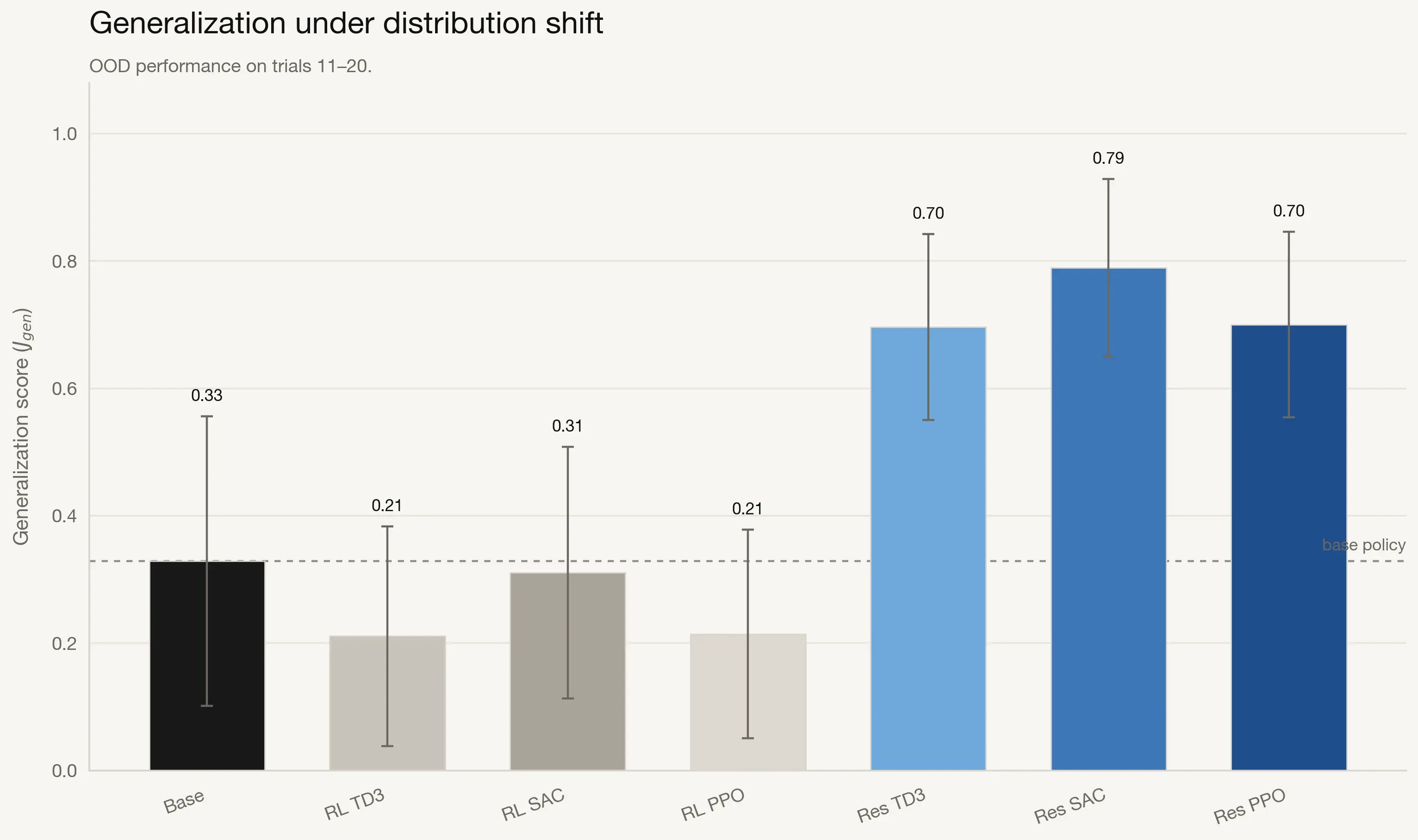
Overall performance comparison across seven tasks. Residual RL methods outperform both the frozen base policy and pure RL baselines in aggregate mean progress and OOD generalization. Error bars denote 95% confidence intervals, and the dashed line indicates base policy reference.
The aggregate plots show a clear hierarchy. Pure RL policies underperform the base policy, with mean progress in the 0.13-0.20 range versus 0.49 for the base. Residual RL methods reverse that trend and deliver substantially higher performance, with Res-SAC reaching 0.78 mean progress, a 59% relative gain over the base policy.
Transfer Gap and Generalization Benefits
To measure adaptation under distribution shift directly, we compute transfer gap as $\\Delta_{gen}$, the OOD performance gain over the frozen base policy.

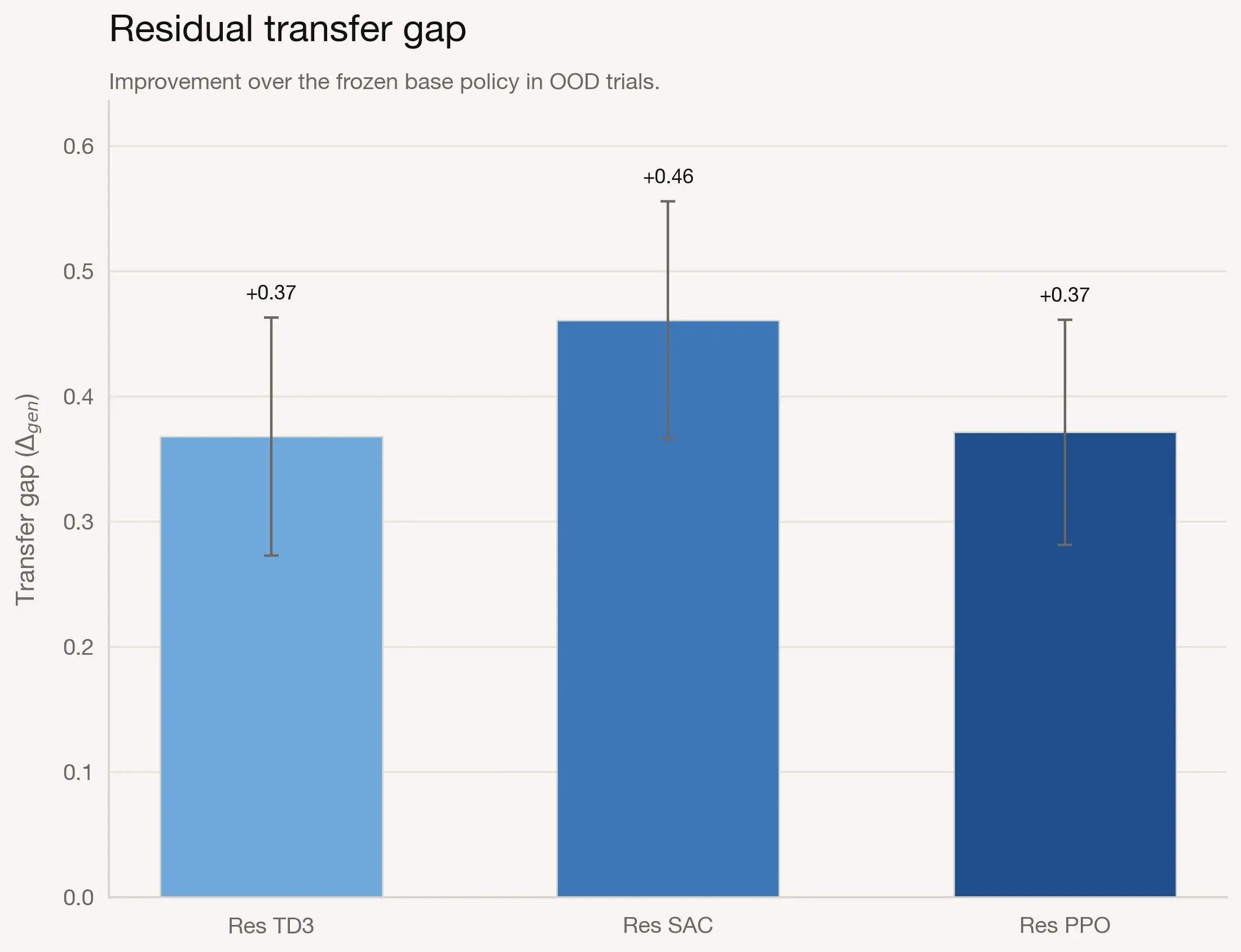
All residual variants show substantial positive transfer: +0.46 (Res-SAC), +0.37 (Res-PPO), and +0.36 (Res-TD3). This supports the central claim that online residual adaptation bridges distribution shift that otherwise degrades frozen policy behavior.
Per-Task Performance Breakdown
Aggregate metrics hide task-specific variation, so we compare the base policy against the best residual method per task.

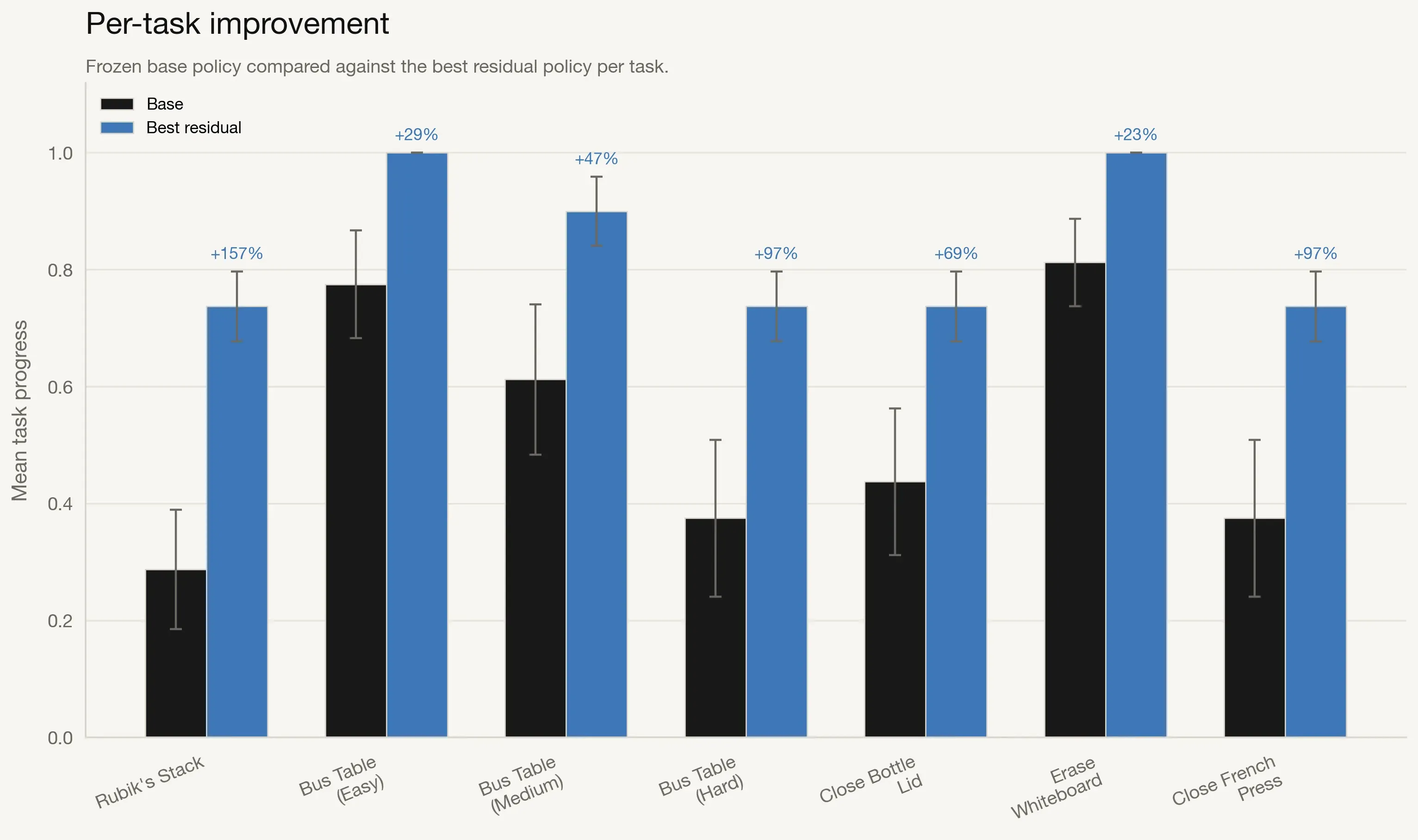
Residual RL improves performance on every task. Improvements are modest where the base policy is already strong (for example, Erase Whiteboard at 18%) and much larger on hard tasks such as Close French Press and Bus Table (Hard), where gains exceed 150%.
Comparison of Residual RL Algorithms
We then compare Res-TD3, Res-SAC, and Res-PPO directly across both aggregate progress and OOD generalization.

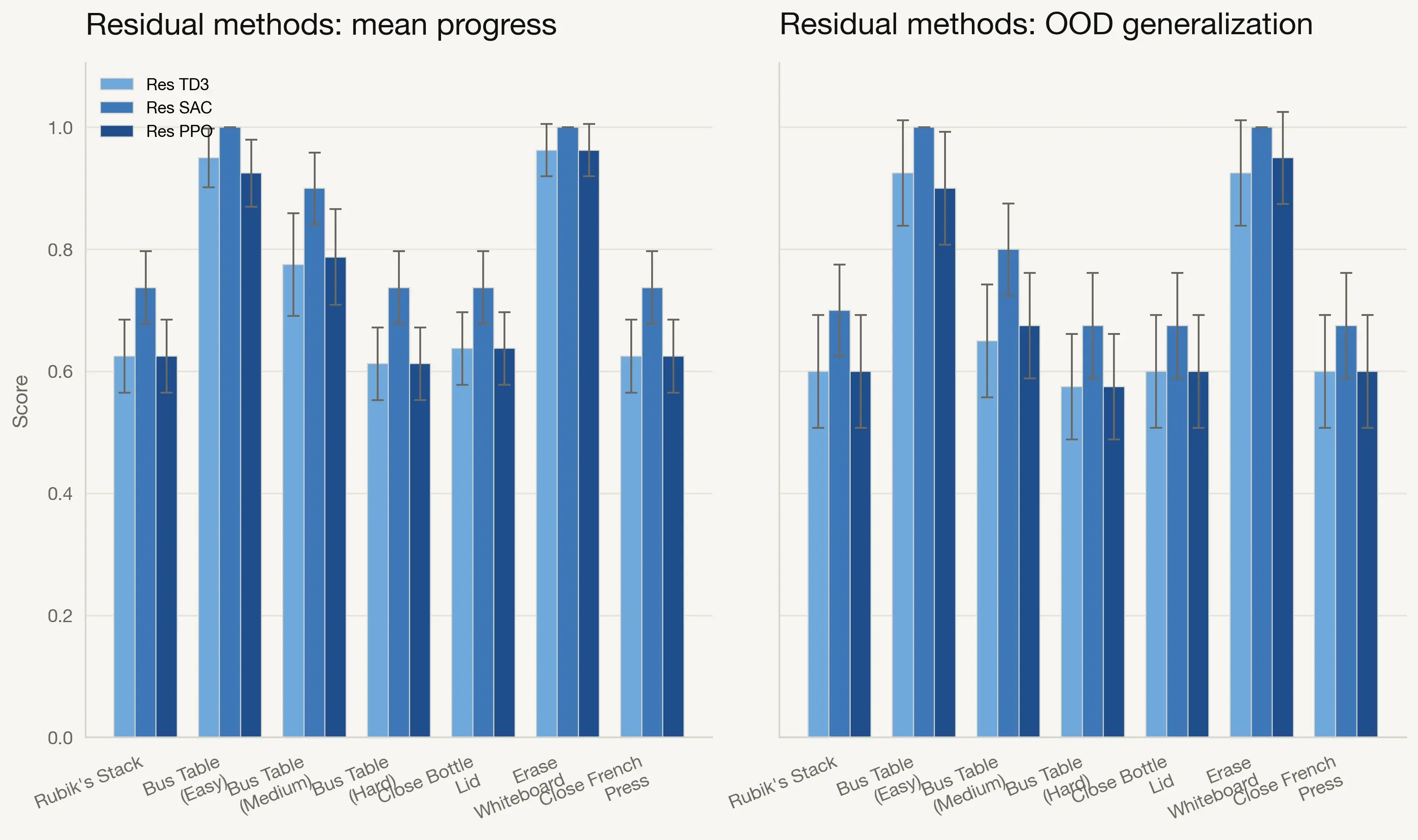
Res-SAC is the most consistent algorithm overall, reaching the highest or near-highest scores on most tasks. Res-TD3 and Res-PPO remain competitive but show larger variance across environments.
Pure RL versus Residual RL
To isolate the effect of residual formulation, we compare each pure RL family to its residual counterpart.

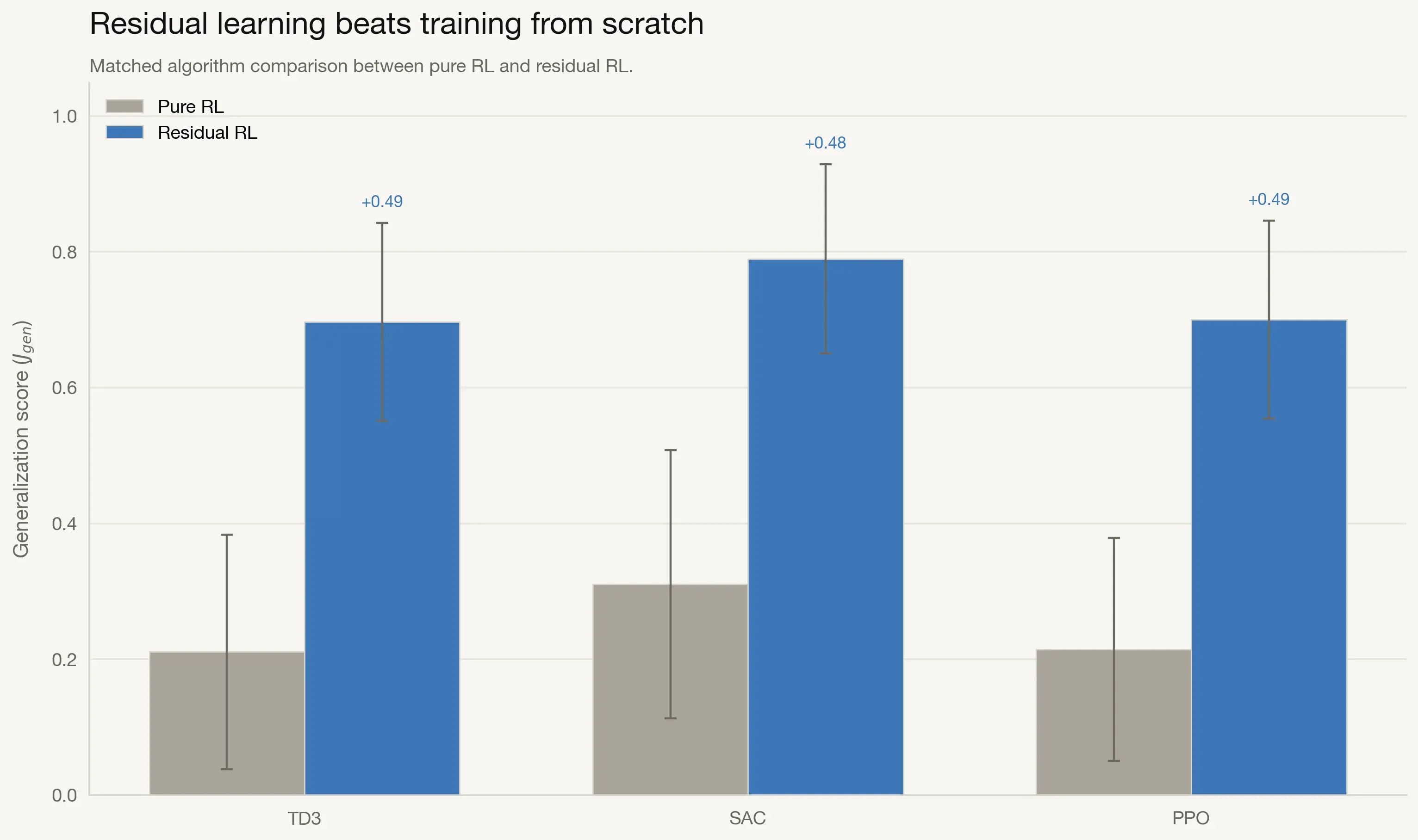
The gains are consistent across algorithm families, indicating that the residual formulation itself drives most of the improvement rather than any one RL optimizer.
Summary of Key Findings
The following summary view emphasizes the practical impact of combining a frozen prior with learned residual correction.

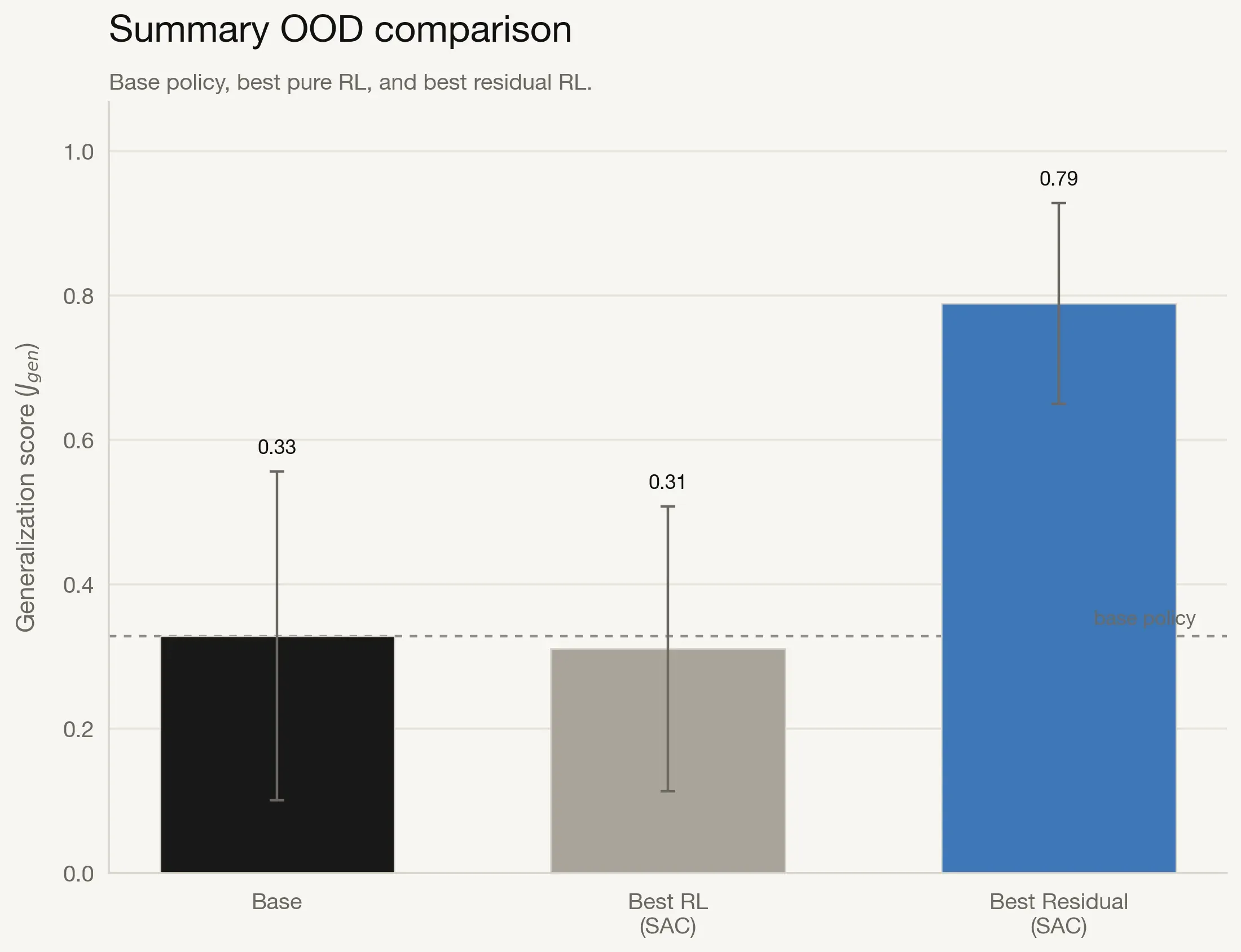
Res-SAC reaches 0.78 generalization, a 134% improvement over the base policy (0.33) and a 200% improvement over pure SAC (0.26). This is the strongest evidence that residual RL preserves pretrained strengths while adding targeted adaptation.
Robustness to Task Difficulty
We also analyze scaling behavior with task difficulty using Bus Table easy, medium, and hard variants.

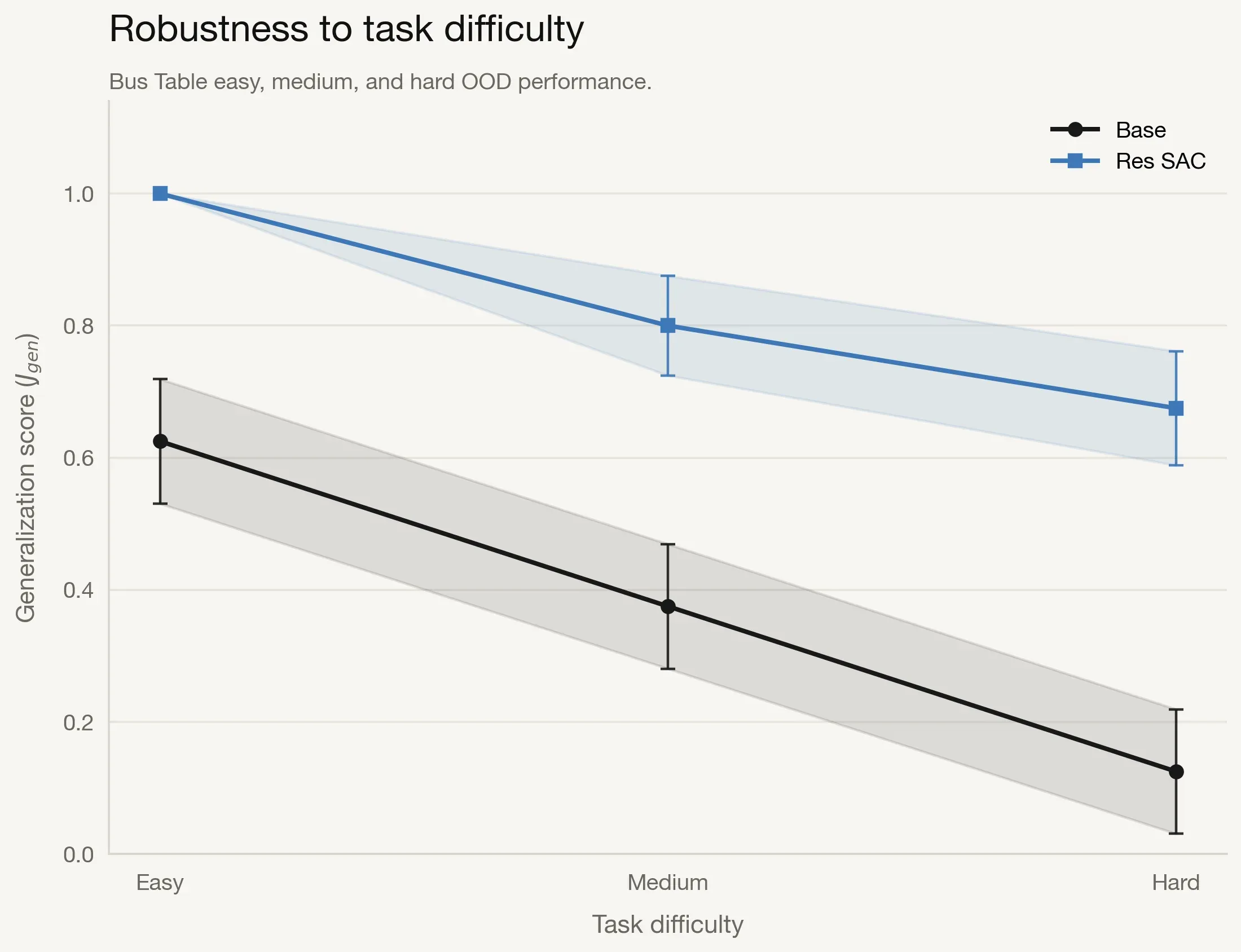
The base policy drops from 0.63 on easy to 0.13 on hard (79% decline), while Res-SAC stays high across the range (roughly 0.68-1.00). The gap widens as difficulty increases, suggesting residual corrections become more valuable in challenging conditions.
Discussion
The results support four practical conclusions:
- Consistent improvements: Residual RL outperforms both the frozen base policy and pure RL across tasks and algorithm families.
- Meaningful transfer gains: Positive transfer gap for all residual methods shows robust OOD adaptation, not marginal noise.
- Difficulty robustness: Residual RL maintains reliability under harder task dynamics where base behavior degrades.
- Recommended default: Res-SAC is the strongest overall choice due to both mean performance and cross-task consistency.
Overall, residual RL provides a practical and effective mechanism to adapt pretrained manipulation policies in real deployment conditions without full policy retraining.
What the Residual Learns
The adapter does not relearn the task. It fixes the last mile. The frozen VLA backbone already provides useful structure. It can identify the object, move toward it, and begin the intended behaviour. The failure usually appears later, when the task becomes physical: contact angle, grip stability, placement, and recovery from small errors.
The residual adapter targets that gap. It learns small action-space corrections while preserving the pretrained policy. In practice, the VLA provides semantic structure and coarse action, while residual RL focuses on local physical corrections that convert near-complete rollouts into robust success.
DTP Ladder
The base policy gets close. The residual controller improves the stages where physical errors compound.
Limitations
This project is deliberately narrow. The goal is not to prove that residual RL solves general robot learning, but to test whether a lightweight residual controller can improve real hardware behaviour when full VLA retraining is unrealistic.
- Tested on one low-cost SO-101 arm
- Fixed external camera setup
- No wrist-mounted camera
- Seven tabletop manipulation tasks
- Controlled lab environment
- TD3, SAC, and PPO only
- One DTP-based reward design
These constraints limit broad generalization, but they make the result practical. The value is showing a viable adaptation layer for frozen VLA policies under a tight physical trial budget.
Future Work
The path to reliable robots may not be bigger generalist policies alone, but better interfaces between priors and experience
This project tests residual adaptation in a deliberately constrained setting. The next step is to scale the same idea across stronger backbones, richer sensing, harder contact dynamics, and more modular robot systems.
Larger VLA backbones
Test residual RL on stronger pretrained policies and compare how much adaptation each backbone needs.
Wrist-mounted vision
Add close-range visual feedback so the adapter can reason through contact, occlusion, and final placement.
Contact-rich manipulation
Move beyond tabletop reaching into tasks with friction, force, deformation, and recovery.
Residual adaptation benchmark
Standardize tasks, rollout splits, DTP scoring, and OOD perturbations so residual methods can be compared cleanly.
Planner plus residual controller
Combine high-level planning with low-level residual correction, so the robot can reason globally and adapt locally.
Module communication
Define cleaner interfaces between the VLA, planner, safety layer, and RL controller.
Citation
If this work is useful in your research, please cite it as:
@misc{barbosa2025realworldrl,
author = {Barbosa, Lucas},
title = {Real-World Reinforcement Learning for Vision-Language Robotic Manipulation},
year = {2025},
month = {November},
howpublished = {Undergraduate Honours thesis, School of Mechanical and Manufacturing Engineering, UNSW Sydney},
note = {Supervisor: Will Midgley}
}